外国色情片 港大马毅:大模子恒久莫得表面就像盲东说念主摸象;大佬都聚谈AI下一步

西风 发自 凹非寺外国色情片
量子位 | 公众号 QbitAI
“我想问在座一个问题,不管是求真书院如故丘成桐少年班的同学,如若这个问题都不知说念,那你就不应该在这个班!”
2024国外基础科学大会“基础科学与东说念主工智能论坛”上,瞎想集团CTO、欧洲科学院外籍院士芮勇此言一出,全场都有些弥留了起来。
但紧接着,他抛出的问题却是:13.11和13.8哪个大?

好家伙,就问谁还不知说念这个梗。
不外,此次不是讥嘲模子失智。来自学界业界的几位AI大牛,分析了模子“幻觉”等等一连串问题,引出了他们对“东说念主工智能的下一步该若何走”的看法。

总结来说,包括以下几个不雅点:
大模子发展下一步要走出“莫得概括智力、莫得主不雅价值、莫得容貌知识”的搜索范式。买卖愚弄过时于模子自身范畴增长,短缺一个超等家具,能信得过把参加的价值体现出来。幻觉罢了下,下一步可以想考如何再扩大模子的泛化性和互动性,多模态是一个采纳。使智能体知说念我方的智力规模,是一个很首要的问题。……
香港大学数据学院院长、香港大学盘算机系系主任马毅在琢磨历程中以致为当今主流在作念的“东说念主工智能”打上了问号:
东说念主工智能本事发展累积了好多的教育,有些我们可以解释,有些我们不可解释,当今恰巧就辱骂常需要表面的时候。实验上以前这十几年我们的scholarship可以说是莫得太多打破的,很大可能是被产业、被工程本事的快速发展影响了学术自身的节拍。

沿途来看大佬们具体都说了啥。
何为智能实质?现场,香港大学数据学院院长、香港大学盘算机系系主任马毅,至极以“记忆表面基石,探寻智能实质”为题发表了主旨演讲。
其中的不雅点与其在圆桌上琢磨的问题一辞同轨。
马毅老师演讲主题是“记忆表面基石,探寻智能实质”,其中纪念了AI历史发展进度,并对刻下AI发展淡薄了我方的看法。

他领先讲了人命与智能的进化。
在他个东说念主看来,人命即是智能的载体,人命能产生能进化,即是智能机制作用的罢了。而且,天下并不是随即的,是可估量的,人命在摆布的进化历程中,学到更多天下可估量的知识。
适者生存适者生涯,这即是智能的一种反馈,访佛于当今强化学习的意见。

从植物到动物、爬行为物、鸟类,再到东说念主类,人命一直在提高我方的智能,但有一个自得,好像智能越高的人命出身以后随从其爸爸姆妈的时代越长。为什么?
马毅老师进一步解释:因为基因不够,一些智力要去学习。学习智力越强,需要学习的东西越多,这才是智能体的更高等时势。
如若以个体方式进行学习,如故不够快不够好,是以东说念主发明了谈话,东说念主的智能变成一个群体智能时势。
产生了群体智能,发生了一个质变。我们不光仅仅从教育不雅测去学习这些可估量的自得,还出现了概括逻辑想维,我们把它叫作念东说念主的智能,或者其后叫作念东说念主工的智能。

接下来,他讲了机器智能的发祥。
上世纪40年代起,东说念主类驱动尝试让机器模拟生物尤其是动物的智能。
东说念主类驱动从神经元建模,探索“大脑感知是若何回事儿”,之后大众发现模拟动物神经系统这件事情应该从东说念主工神经汇聚去搭建合座,估量变得越来越复杂。

这件事情并不是一帆风顺,中间阅历了两个穷冬,大众发现了神经汇聚的一些局限性,有些东说念主仍在坚握处置这些挑战。
之后数据算力发展,进修神经汇聚变成了可能,越来越深的汇聚驱动发展起来,性能越来越好。
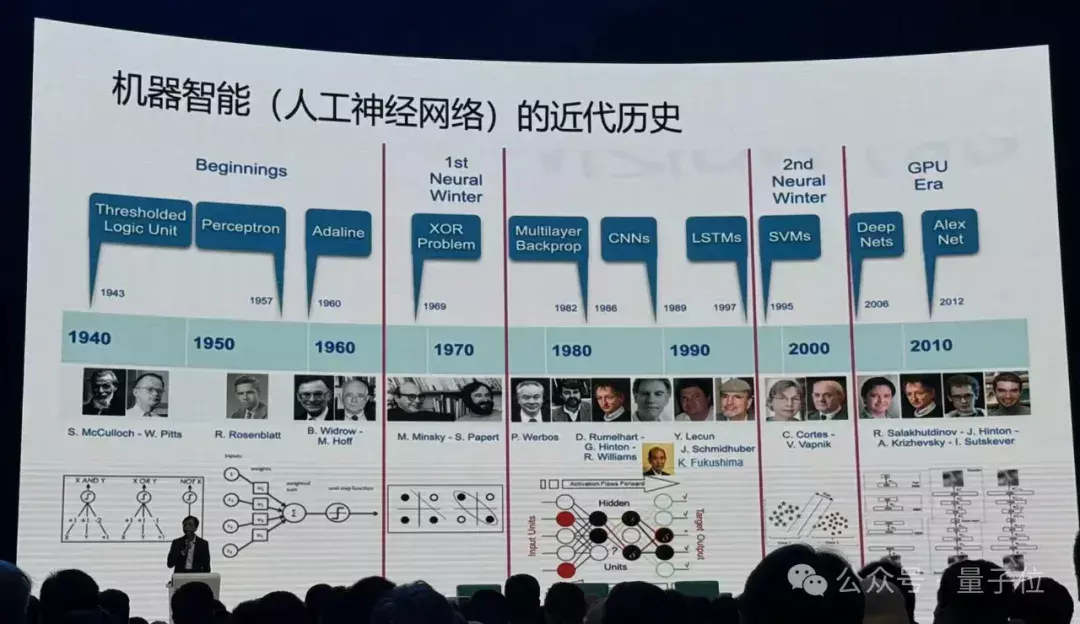
但有个最大的问题:这些汇聚都是教育假想的,它是个黑盒子,而且这个盒子越来越大,东说念主们不知说念内部在干什么。
黑盒有何不好?从本事角度,教育假想也可以,可以摆布试错。但是其中代价很大,周期很长,罢了很难控。此外:
只须这个天下上有大众解释不了的但是很首要的自得,好多东说念主被蒙在饱读里,就会制造错愕,当今这个事情正在发生。
是以,如何把黑盒掀开?马毅老师淡薄要回到底本的问题:为什么要学习?人命为什么能进化?
他至极强调,一定要谈能通过盘算收场的东西:
不要谈任何概括的东西,这是我给大众的建议,你一定要谈若何去盘算,若何去引申这件事情。

是以要学什么?
马毅老师认为外国色情片,要学可估量的限定性的东西。
比如手里拿着一根笔,一铁心,大众都知说念会发生什么,而且看成快的话还能收拢。这在牛顿之前即是已知的。东说念主和动物貌似都是对外部天下作念了很好的建模。
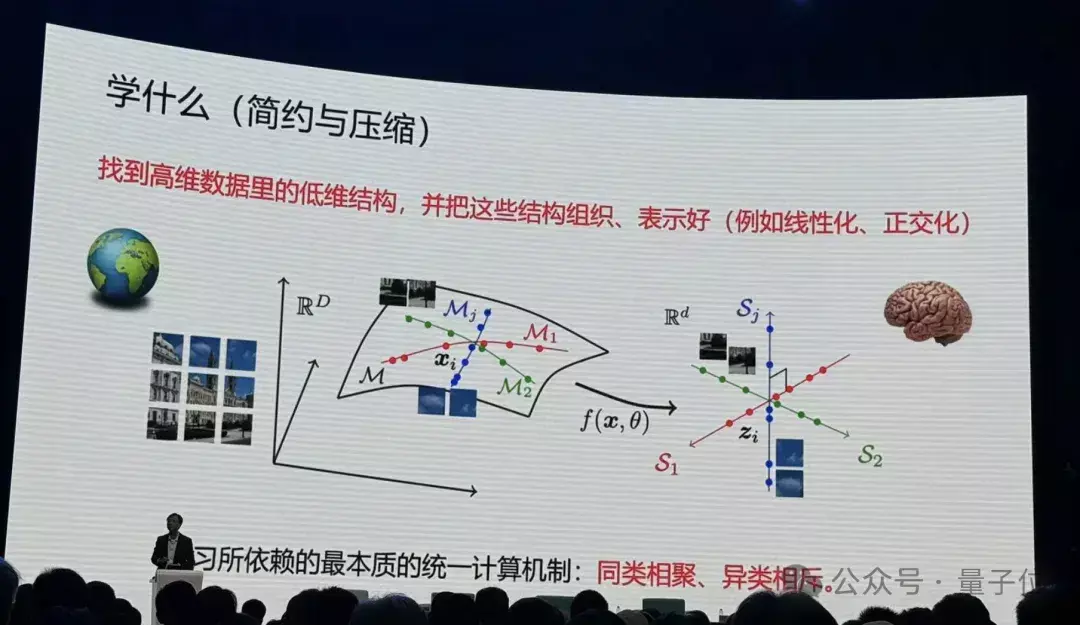
而在数学上,可估量的信息都和解以数据在高维空间中的低维结构体现出来。
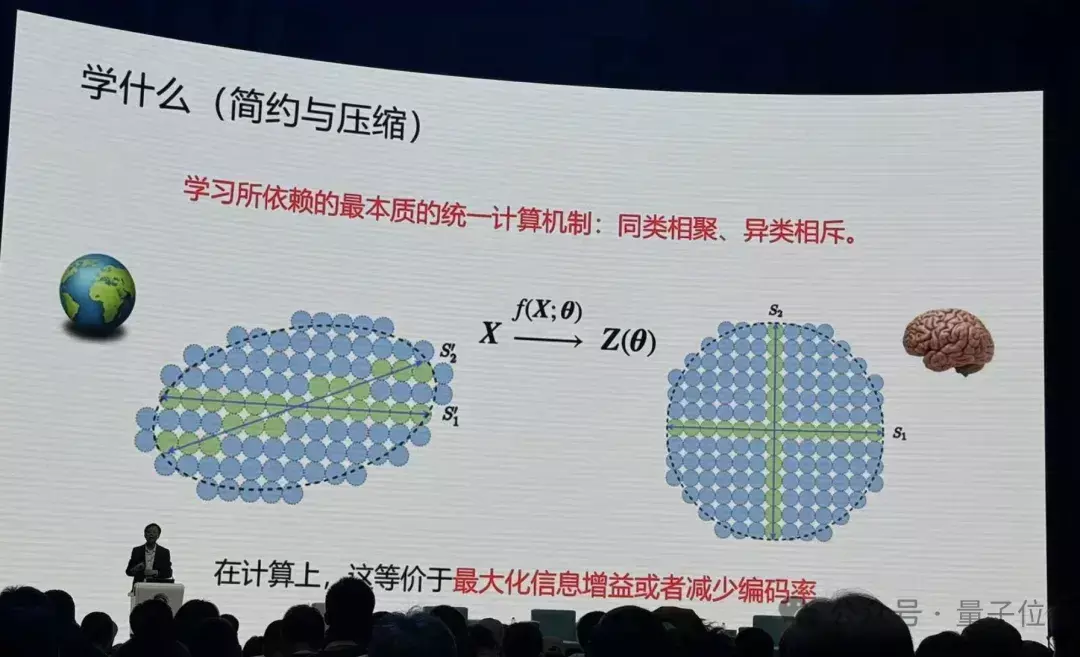
那么和解的盘算机制是什么?马毅老师给出了恢复:同类相聚、异类相斥,实质就这样松懈。
如何度量作念的好不好?为什么要压缩?
他举了个例子,如下图。比如说天下是随即的,什么都不知说念,通盘的事情皆可发生,如若用蓝色球代替,下一秒钟通盘蓝色球都是可能发生的。
但如若要记取其中一件事情发生,就要对通盘这个词空间编码,给它一个代码,唯一绿色球的区域才可能发生,蓝色球的部分就会少好多。
当我们知说念的会发生的区域越细后,我们对这个天下的未知就变得越来越少,40年代信息表面即是在建树这个事情。
要想更好找到这些绿色区域,就要在大脑内部把它组织的更好。是以我们的大脑是在对这种自得,对这个低维的结构在作念这种组织。
在盘算上如何收场这个方针?
马毅老师暗示,通盘深度汇聚实验上都在作念这件事情。像当今Transformer,对图像进行分割,进行分类识别,就在作念这个事情。
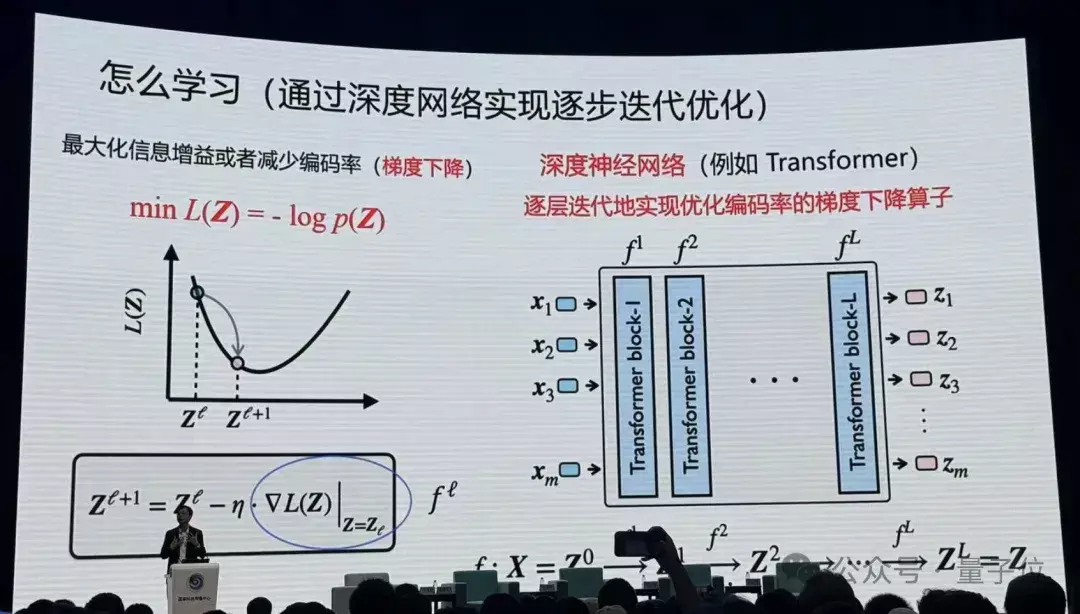
实验上神经汇聚每一层即是在压缩数据。
在这当中数学起到十分首要的作用,你去严格度量要优化什么东西,严格去讲若何去优化,当你把这两件事作念完以后,你会发现你获得的算子跟当今教育找到的好多算子十分相似。
Transformer也好,ResNet也好, CNN也好,都是作念这件事情以不同的收场方式。而且在统计、几何上都备可以解释它在干什么。

但优化自身最优解有时是正确解,在压缩历程中可能丢掉了首要信息,若何阐发现存的信息维度是好的呢?若何阐发不会产生幻觉?
回到学习的根底,我们为什么要记取这些东西?是为了要在大脑里对物理天下作念仿真,为了更好地在物理空间中进行估量。
之后马毅提到了对都这一意见:
是以对都不是跟东说念主对都,对都是这个模子我方跟我方学到的东西对都。
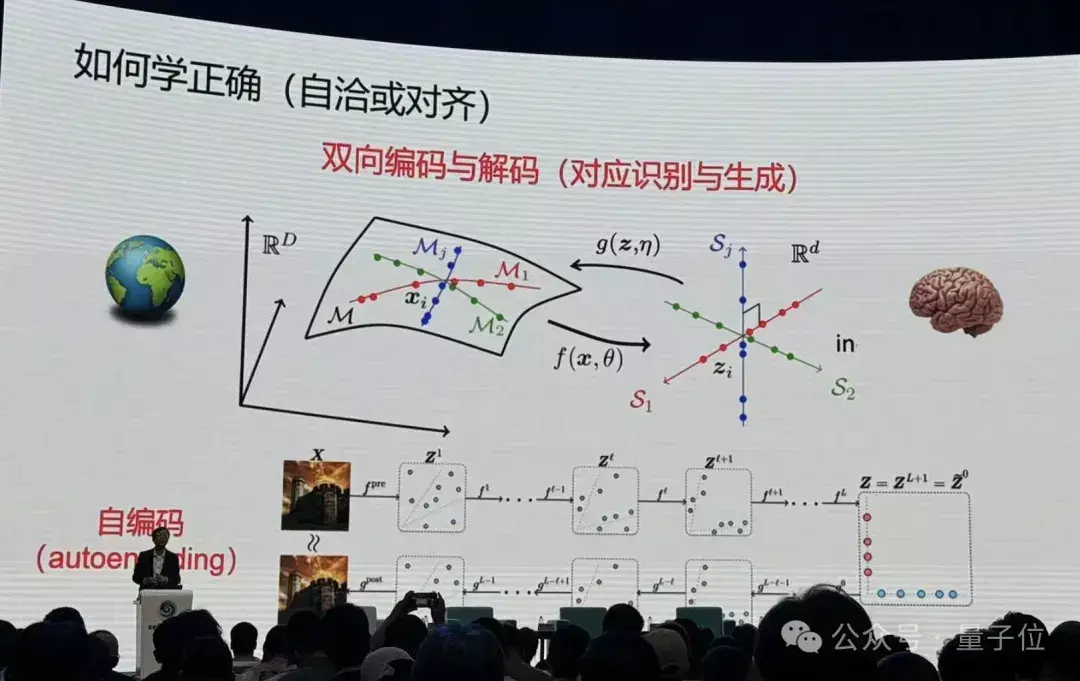
从里到外双方学到一个autoencoding并不够,当然界的动物是如何学习外部天下的物理模子的——
摆布通过我方的不雅测,去估量外部天下,只须和不雅测是一致的,就可以了。这就波及到一个闭环的意见。
只须辞世的生物,只须智能的生物,26uuu.com全是闭环性。
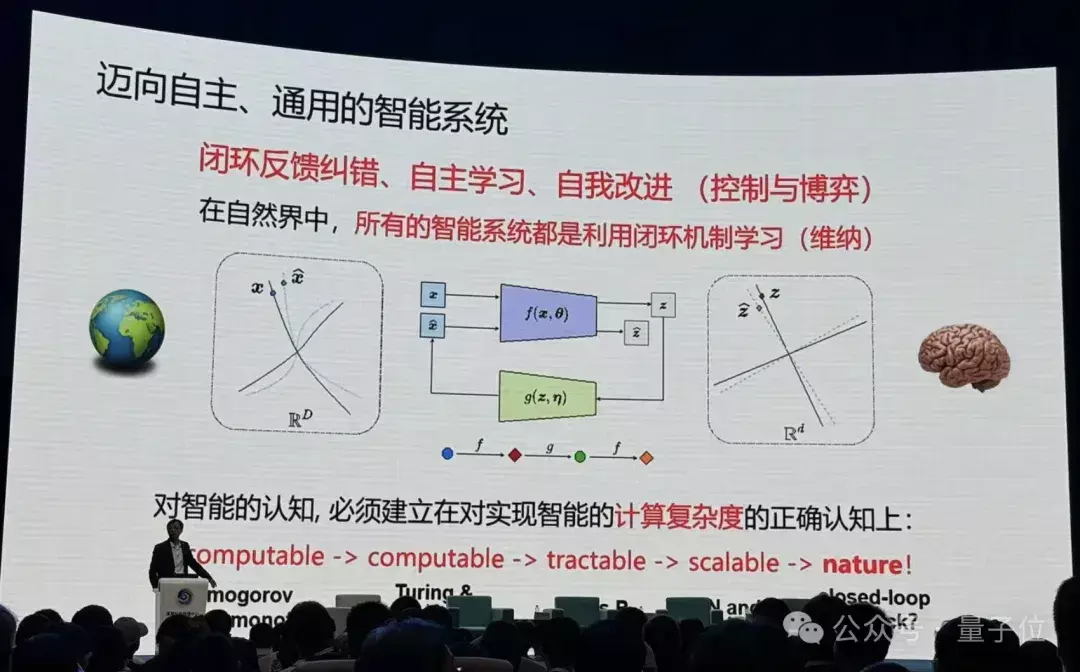
之后马毅老师引出,我们离信得过的智能还差很远。
什么是智能?大众接续把知识和智能混在沿途,一个系统有知识即是有智能吗?一个智能系统,必须具备自我阅兵、加多我方知识的基础。
临了马毅老师进行了总结。
纪念历史,40年代大众都想让机器去师法动物,但是50年代图灵淡薄了一件事——机器能不可像东说念主类相同想考。1956年达特茅斯会议,一群东说念主坐在沿途,他们的方针即是一定要作念东说念主分歧于动物特有的智能:概括智力、绚丽运算、逻辑推理、因果分析等。
这是1956年他们界说的东说念主工智能要作念的事情,其后这些东说念主基本上都得图灵奖。是以你以后要得图灵奖,是采纳去从众如故作念一些特等的东西……
回看我们以前10年到底在干什么?
刻下的“东说念主工智能”在作念图像识别、图像生成、文本生成、压缩去噪、强化学习,马毅老师认为,从基础上我们作念的事情即是动物这一层的事情,包括估量下一个token、下一帧图像。
不是说其后我们莫得东说念主在作念。但不是主流的大模子。

他进一步解释,实足多的钱砸进去,实足的数据砸进去,模子好多的性能如故会赓续发展,但是恒久莫得表面会出现问题,就像盲东说念主摸象。

马毅老师暗示,共享其个东说念主的这段历程,但愿能给年青东说念主一些启发。
有了旨趣我们就可以踊跃去假想,就不再等着下一代谁再发明一个好像可以的汇聚,我们再沿途用。那你的契机在那里呢?
底下来看圆桌论坛中,其他AI大牛对“东说念主工智能下一步该若何走?”这个问题是如何恢复的。
东说念主工智能下一步该若何走?大模子要有“范式”的变化英国皇家工程院院士、欧洲科学院院士、香港工程科学院院士、香港科技大学首席副校长郭毅可认为,我们当今处于一个十分真谛的时刻——
因为Scaling Law被平凡袭取,百模大战缓缓酿成了一个资源大战。看似当今只需要作念两件事,有了Transformer模子以后,要处置的即是大算力和大数据的问题。
但是,在他看来事实并非如斯。当下AI发展还濒临好多问题,其一是有限算力和无限需求的问题。
在这种情况下,应该如何作念大模子?郭院士通过一些实践,共享了我方的想考。
领先郭院士提到了在算力罢了下,接收更经济的MOE搀杂大众模子也能达到很好的罢了。

此外,如何把一个模子训完之后,摆布用新的数据改善,让它大要把该记取的记取,该忘的忘了,而且在需要的时候还大要难忘还是忘了的东西,亦然一个很难的问题。
关于业界的一些“数据还是是用完了”的说法,郭院士暗示不认可,“实验上仅仅变成了模子被压缩了,而压缩好的数据可以再生成新的数据”,也即是用生成模子来生成数据。
接着,不是通盘东西模子都要从新学习,可以把知识镶嵌到基础模子内部。这方面也有好多使命要作念。
除了算力,算法上还有一个问题:机器智能和东说念主类智能自身的培养具有南北极性。
郭院士认为,进修大模子,更首要的问题不在前边,而是在后头。
如下图所示,大模子的进化旅途是从自我学习>盘曲知识>价值不雅>知识,而东说念主类耕种的培养旅途与之相背。

正因为如斯,郭院士认为应该走出今天大模子“莫得概括智力、莫得主不雅价值、莫得容貌知识”的搜索范式。
我们都知说念东说念主类的谈话是伟大的,东说念主类谈话内部不仅是内容,不仅是信息,更多的是东说念主性,是信息的能量,那么这些东西如何归类到模子中去?是我们改日估量的一个首要的标的。

总结来说,关于东说念主工智能下一步该若何走,郭院士认为有三个发展阶段:
第一个阶段以确切性为本;第二个阶段以价值为本,机器要有智力敷陈我方的不雅点,要酿成我方的一种主不雅价值,而况这个不雅点可以凭证它的环境来改动;第三当它有了价值不雅以后,才懂得什么是新奇,有了新奇才可能进行创造。
到了创造这个模式,所谓的幻觉不是问题,因为幻觉唯一在范式模式下才是个问题。写演义一定是幻觉,莫得幻觉,写不出演义来,它只须保握一致性,不需要确切性,是以只须反应一种价值就可以了,是以从这个深嗜上来讲,大模子的发展实验上要有范式的变化。
大模子发展缺一个“超等家具”京东集团副总裁、华盛顿大学兼职老师、博士生导师何晓冬认为AI下一步濒临三个问题。
领先,他认为从某种深嗜上来说当今大模子发展进入了一个平台期。
由于数据和算力罢了,如若松懈基于范畴来升迁,有可能达到天花板,算力资源也会成为一个越来越重的职守。如若按照最新的价钱战(标价),很可能大模子产生的经济效益连电费都隐敝不了,那么当然是不可握续的。
其次,何老师认为通盘这个词买卖愚弄有些过时于模子自身的范畴增长,中恒久来看,这终将会成为一个问题:
至极是我们看到这样大范畴的时候,他不再松懈是一个科学问题,它也会成为一个工程问题,比如说参数到了万亿级,调用数据到10万亿token级别。那么势必需要淡薄一个问题:它带来的社会价值。
由此,何老师认为刻下短缺一个超等愚弄和超等家具,大要信得过把参加的价值体现出来。
第三个问题是一个相对相比具体的问题,即大模子幻觉。
如若我们想在大模子之上开导一个AI产业大厦,就要对基础大模子幻觉有极高的条件。如若基础大模子失实率很高,那么很难想象这上头可以重复更多买卖愚弄。
严肃的产业愚弄是需要处置幻觉的。
何老师认为在幻觉罢了下,下一步可以想考如何再扩大模子的泛化性和互动性,而多模态是一个势必的采纳。
 大模子短缺“智力规模”理解
大模子短缺“智力规模”理解瞎想集团CTO、欧洲科学院外籍院士芮勇从工业界视角,给出了他对AI下一步的看法。
他暗示,从工业界来看,更首要的是模子如何落地。在落处所面,芮勇博士主要讲了两点:
光有大模子是不够,一定要发展智能体。光有云测大模子亦然不够,需要有一个搀杂框架。
具体来说,芮勇博士领先列举了一些估量,并指出大模子刻下局限性越来越彰着。比如起原提到的“13.8和13.11哪个大”的问题,可以看出模子莫得信得过纠合问题。
在他看来,刻下大模子其实仅仅把在高维语义空间里看到的海量碎屑信息勾搭起来,光靠堆砌大算力大汇聚来造生成式大模子是不够的,而下一步应该朝着智能体的标的发展。
芮勇博士至极强调了大模子智力规模问题。
今天的大模子其实并不知说念它我方的智力规模在哪。
为什么大模子会出现幻觉,为什么会一册稳固瞎掰八说念?其实它不是想骗我们,而是不知说念我方知说念什么,也不知说念我方不知说念什么,这是一个很首要的问题,是以我以为第一步要使智能体知说念我方的智力规模。
此外,芮勇博士暗示AI落地光有智能也不够,云上的公有大模子需要面向企业进行独到化。数据驱动加上知识驱动,酿成搀杂的AI模子,而且小模子在很厚情况下也十分有效,还有面向个东说念主的模子,大要知说念个东说念主的喜好。
它将不是都备基于云测的大模子,而是一个搀杂的端边云相结合的大模子。
— 完 —
量子位 QbitAI · 头条号签约外国色情片